Pipeline Method
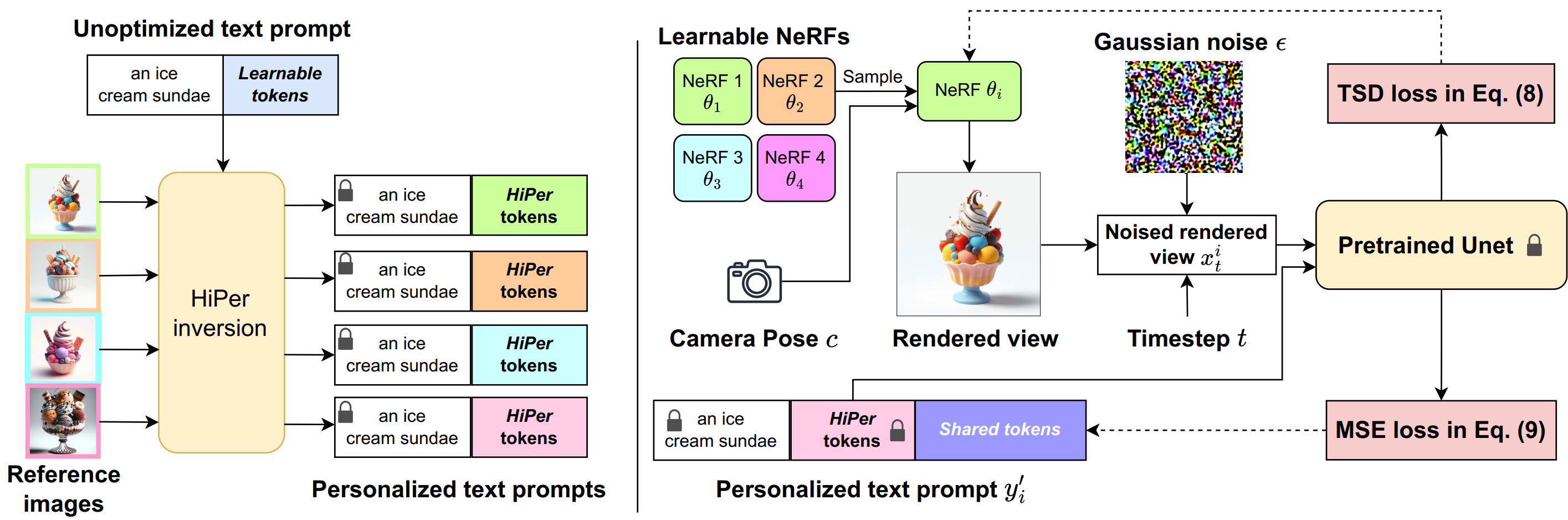
We translate the diversity of augmented text prompts to the resulting 3D models via a two-stage method.
Stage 1: HiPer tokens inversion (left): for each reference image, we seek to learn a HiPer token $h_i$ so that the prompt $[y; h_i]$ reconstructs the reference image.
Stage 2: Textual score distillation (right): we run a multi-particle variational inference for optimizing the 3D models from text prompt $y$. For each iteration in the optimization, we randomly sample a particle $\theta_i$ with its rendered image $x_i$. We use the augmented text prompt $y'_i = [y; h^*_i;\phi]$, with $\phi$ as shared embedding to condition the optimization of $\theta_i$.
These two are taken as input to a pretrained Stable Diffusion to compute the TSD loss and MSE loss to update the NeRF and shared learnable token $\phi$ iteratively.